SQL 查询的执行顺序
by emanjusaka from https://www.emanjusaka.top/2023/09/sql-query-order 彼岸花开可奈何
本文欢迎分享与聚合,全文转载请留下原文地址。
前言
了解 SQL 查询的执行顺序对我们解决一些问题很有帮助,有时我们可能会疑惑为什么不能对分组的结果进行筛选这样类似的问题?之前一直不是理解这个问题,在了解了SQL 查询的执行顺序之后这个问题也就迎刃而解。在我们对 SQL 查询语句进行分析优化时,掌握执行顺序也是有一定帮助的。
一、理论顺序
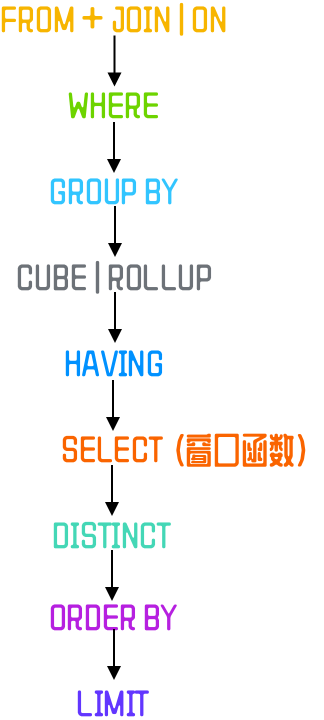
上面是图示 SQL 的执行顺序,下面用列表列出:
FROM
ON
JOIN
WHERE
GROUP BY
CUBE | ROLLUP
HAVING
SELECT
DISTINCT
ORDER BY
LIMIT
上面所列出的执行顺序能帮助我们解答一些问题:
为啥不能对窗口函数的执行结果进行过滤?
因为窗口函数在 SELECT 步骤执行,而这步是在 WHERE 和 GROUP BY 之后
可以对分组的结果进行筛选吗?
不可以,因为 GROUP BY 在 WHERE 之后执行
可以对分组后的结果进行排序吗?
可以,因为 ORDER BY 在 GROUP BY 之后。
二、代码示例
学生表
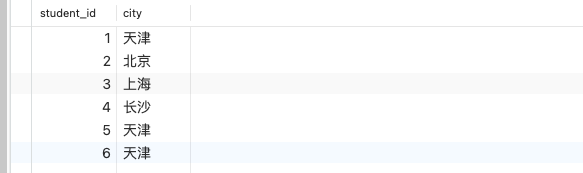
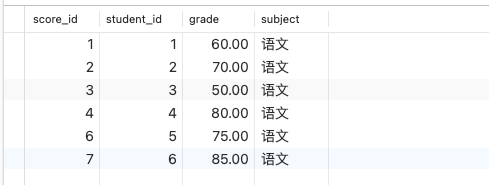
成绩
查询语句
查询来自天津且总成绩高于70分,并且查询他们的总成绩,查询结果按成绩降序排列
SELECT ss.student_id,sum(se.grade) as total,ss.city FROM students ss LEFT JOIN score se ON ss.student_id = se.student_id WHERE ss.city = "天津" GROUP BY ss.student_id HAVING sum(se.grade) > 70 ORDER BY total DESC LIMIT 10
查询结果

三、分析 SQL 执行过程
SQL 运行的每个操作都会产生一张虚拟表,只不过这些虚拟表对用户是透明的,只有最后一步生成的虚拟表才会返回给用户。
第一步执行的是对 FROM 字句前后的两张表 students 和 score 进行笛卡尔积操作,生成虚拟表VT1。
应用 ON 过滤器
在虚拟表 VT1 中执行过滤操作,过滤条件为:ss.student_id = se.student_id
对于在 ON 过滤条件下的 NULL 值比较,此时的比较结果为 UNKNOWN,却被视为 FALSE 来进行处理,即两个 NULL 并不相同。但是在下面两种情况下认为两个 NULL 值的比较是相等的:
GROUP BY 子句把所有 NULL 值分到同一组
ORDER BY 子句中把所有 NULL 值排列在一起
在产生虚拟表 VT2 时,会增加一个额外的列来表示 ON 过滤条件的返回值,返回值有 TRUE、FALSE、UNKNOWN。取出比较值为 TRUE 的记录,产生虚拟表 VT2。
添加外部行
这一步只有在连接类型为 OUTER JOIN 时才发生,如 LEFT OUTER JOIN、RIGHT OUTERJOIN、FULL OUTER JOIN。虽然在大多数时候我们可以省略 OUTER 关键字,但 OUTER 代表的就是外部行。LEFT OUTER JOIN 把左表记为保留表,RIGHT OUTER JOIN 把右表记为保留表,FULL OUTER JOIN 把左右表都记为保留表。添加外部行的工作就是在 VT2 表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予 NULL 值,最后生成虚拟表 VT3
应用 WHERE 过滤器
对上一步骤产生的虚拟表 VT3 进行 WHERE 条件过滤,只有符合<where_condition>的记录才会输出到虚拟表 VT4 中
在当前应用 WHERE 过滤器时,有两种过滤是不被允许的:
由于数据还没有分组,因此现在还不能在 WHERE 过滤器中使用 where_condition=MIN(col)这类对统计的过滤
由于没有进行列的选取操作,因此在 SELECT 中使用列的别名也是不被允许的,如 SELECT city as c from students WHERE c = '天津' 是不允许出现的
分组
在本步骤中根据指定的列对上个步骤中产生的虚拟表进行分组,最后得到虚拟表 VT5
应用 HAVING 过滤器
在该步骤中对于上一步产生的虚拟表应用 HAVING 过滤器,HAVING 是对分组条件进行过滤的筛选器。生成虚拟表VT6。
处理 SELECT 列表
在这一步中,将 SELECT 中指定的列从上一步产生的虚拟表中选出生成虚拟表 VT7。
应用 ORDER BY 字句
根据 ORDER BY 子句中指定的列对上一步输出的虚拟表进行排列,返回新的虚拟表 VT8。
注意:在 MySQL 数据库中,NULL 值在升序过程中总是首先被选出,即 NULL 值在 ORDER BY 子句中被视为最小值
LIMIT 子句
在该步骤中应用 LIMIT 子句,从上一步骤的虚拟表中选出从指定位置开始的指定行数据。对于没有应用 ORDER BY 的 LIMIT 子句,结果同样可能是无序的,因此 LIMIT 子句通常和 ORDER BY 子句一起使用。
四、注意
上面所讨论的顺序皆为理论上的执行顺序,实际上数据库引擎并不是通过连接、过滤和分组来运行查询,因为它实现了一系列优化来提升查询速度(不影响最终的返回结果)。数据库引擎可能会为了提高查询的速度把一些过滤条件进行提前,当然前提是不会对返回的结果造成影响。
SELECT
ss.student_id,sum(se.grade) as total,ss.city
FROM
students ss
LEFT JOIN score se ON ss.student_id = se.student_id
WHERE
ss.city = "天津"
这个 sql 学生城市是天津的只有三个,如果在学生很多的情况下如果先做城市的筛选后再对两张表做笛卡尔积可以很大程度的提升性能,并且也不会对返回的结果造成影响。这时实际上SQL的执行顺序可能就与理论上的执行顺序不一样了。
参考资料
本文原创,才疏学浅,如有纰漏,欢迎指正。尊贵的朋友,如果本文对您有所帮助,欢迎点赞,并期待您的反馈,以便于不断优化。
原文地址: https://www.emanjusaka.top/2023/09/sql-query-order
微信公众号:emanjusaka的编程栈



