Java 中堆内存和栈内存上的数据分布和特点
by emanjusaka from https://www.emanjusaka.top/2024/07/java-heap-stack-distribution-feature 彼岸花开可奈何
本文为原创文章,可能会更新知识点以及修正文中的一些错误,全文转载请保留原文地址,避免未即时修正的错误误导。
经常有人把 Java 内存区域笼统地划分为堆内存(Heap)和栈内存(Stack),这种划分方式直接继承自传统的 C、C++程序的内存布局结构,在 Java 语言就显得有些粗糙了,实际的内存区域划分是要更复杂一下。如下所示:
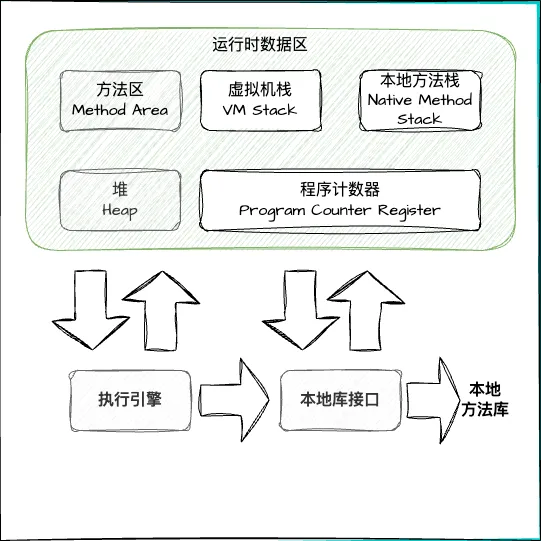
方法区、堆是由所有线程共享的数据区。虚拟机栈、本地方法栈和程序计数器是线程隔离的数据区。
我们最关注的、与对象内存分配关系最密切的区域是“堆”和“栈”两块。其中“栈”通常就是指这里的虚拟机栈,更多情况下只是指虚拟机栈中局部变量表部分。下面我们详细分析一下堆内存和栈内存的数据分布。
问题:哪些数据放在栈上,哪些数据放在堆上?
如果你擅长 Java 这种内存自动管理的语言,这个问题很好回答。
栈上的数据:
基本数据类型(boolean、byte、char、short、int、float、long、double)
对象引用(reference 类型,它并不等同于对象本身,可能是一个指向对象起始地址的应用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)
returnAddress 类型(指向了一条字节码指令的地址)
堆上数据:
普通对象:各种类的实例。
数组:数组是一种特殊类型的对象,可以存储多个相同类型的元素。
基本类型包装器对象:Java 提供了一些基本类型的包装器类:如 Integer、Double、Character 等。
栈和堆内存上的数据特点
我们先来分析下程序中的栈和堆,然后总结出它们的特点。
Stack
栈的数据结构特点是先进后出。由于这个特点,非常适合记录程序的函数调用,也称为函数调用栈。函数调用栈从下到上增长,每当函数执行时,就会在栈顶部分分配一块连续的内存,称为帧。这个帧存储了当前函数的通用寄存器和当前函数的局部变量的上下文信息。下面给出一个简单的 Java 函数调用,我们分析一下这个过程:
public class StackExample {
public static void main(String[] args) {
int result = add(3, 5);
System.out.println("结果是: " + result);
}
public static int add(int a, int b) {
return a + b;
}
} 在这个例子中,main函数调用了add函数。当main函数开始执行时,会在栈内存中为main函数分配一块空间,包括局部变量result和参数args。然后,main函数调用add函数,此时会在栈内存中为add函数分配另一块空间,包括局部变量a、b和返回地址。当add函数执行完毕后,其占用的栈空间会被释放,控制权返回给main函数。最后,main函数执行完毕,整个程序结束。
通常情况下,它需要连续的内存空间,这意味着程序在调用下一个函数之前必须知道下一个函数需要多少内存空间。但是程序是怎样知道的呢?
答案是编译器为我们完成了这一切。当编译代码时,函数是一个最小的编译单位。每当编译器遇到一个函数时,它就知道当前函数使用寄存器和局部变量所需的空间。
因此,无法在编译时确定大小或可以更改大小的数据是不能安全地放置在栈上的。
Heap
有些数据不能安全地放在栈上,所以最好放在堆上,比如下面的ArrayList:
import java.util.ArrayList;
public class VariableLengthArrayExample {
public static void main(String[] args) {
// 创建一个空的 ArrayList
ArrayList<Integer> arrayList = new ArrayList<>();
// 向 ArrayList 中添加元素
arrayList.add(1);
arrayList.add(2);
arrayList.add(3);
// 输出 ArrayList 的大小
System.out.println("Size of the ArrayList: " + arrayList.size());
// 访问 ArrayList 中的元素
for (int i = 0; i < arrayList.size(); i++) {
System.out.println("Element at index " + i + ": " + arrayList.get(i));
}
// 删除 ArrayList 中的一个元素
arrayList.remove(1);
// 再次输出 ArrayList 的大小和内容
System.out.println("Size of the ArrayList after removal: " + arrayList.size());
for (int i = 0; i < arrayList.size(); i++) {
System.out.println("Element at index " + i + ": " + arrayList.get(i));
}
}
}
当创建一个ArrayList 时,程序需要动态的分配内存。如果数组的实际使用量超过了这个容量,程序会分配一个更大的内存块,将现有元素复制到其中,添加新元素,然后释放旧内存。此过程允许数组根据需要动态调整大小。请求系统调用并找到新的内存然后一一复制的过程是非常低效的。所以这里最好的做法是提前预留需要的空间。
另外,需要跨栈引用的内存也需要放在堆上,这很好理解,因为一旦一个栈帧被回收,其内部的局部变量也会被回收,所以在不同的调用栈中共享数据只能使用堆。
总结
栈上存储的数据是静态的,大小固定,生命周期固定,线程隔离不能跨栈引用。
堆上存储的数据是动态的、不固定大小、不固定生命周期、线程共享可以跨栈引用。
参考资料
《深入理解 Java 虚拟机(第 3 版)》——周志明

在技术的星河中遨游,我们互为引路星辰,共同追逐成长的光芒。愿本文的洞见能触动您的思绪,若有所共鸣,请以点赞之手,轻抚赞同的弦。
原文地址: https://www.emanjusaka.top/2024/07/java-heap-stack-distribution-feature
微信公众号:emanjusaka的编程栈

